Step
Created: May 20, 2021, Updated: July 13, 2023
Step describes what happens to the tables on the borderlines of two stages. From simple tasks as renaming a table or specifying different kex for a specific table to the more complex ones, such as incrementally extracting and processing data and making snapshots, step is there to make Bizzflow event more powerful.
If you take a look at the picture in Warehouse Structure, you may notice we simply accept that data gets copied between stages with no way of specifying how the copy should be processed. With step, you may parametrize each transition of each table between any two stages.
About Step
In the whole ETL proces, each step is responsible for copying and processing data between two consecutive stages, i.e.:
- from raw to input
- from input to
transienttransformation - from
transienttransformation to output - from output to datamart
Steps are declarative data operations (you can call it “transformations”), which defines, what operation should be done during processing data from one stage to next stage. For example, when you copy data from raw stage to input stage, you want remove sensitive attributes from data by whitelisting only attributes, which will continue in next stages. Yes, you can do it as a part of transformation, but in step definition, you can do it more efectively, because you have to only attributes, which are whitelisted. Also using steps is more secure, because user has no direct access into raw stage, only via Storage Console.
Another example is, you want to rename tables or make simple union of tables with the same structure into one big table (for example, each branch has separate database).
Step configuration
You can configure what happens between the two consecutive phases in the step configuration json in your project repository. There are four possible types of operations determining how individual tables should be treated:
- union
- whitelist
- filter
- copy
To configure what happens with the particular table between two stages, specify individual table configuration by placing the table configuration into the {} of desired action - "union": {}, "whitelist": {}, "filter": {} or "copy": {} in the step.json in your project repository. If union, whitelist or filter is performed on the table, it must always be included in "copy": {} as well. If you combine the operations for a single table, the order is as follows: union, whitelist, filter, copy.
Default table behavior, if not included in step configuration
If not configured in the step.json, default operation is to copy the whole table between two consecutive stages:
- raw -> in (load):
raw_prefix in the kex name is replaced byin_prefix, i.e. only the prefix differs in the source and destination kex name, table name remains unchanged - tr -> out (output mapping): Output mapping is performed only for tables with
out_prefix in the table name. During output mapping theout_prefix is removed from table name, e.g`tr`.`out_some_table`created in your transformation query would land in`out_kex_whatewer`.`some_table`, whereout_kex_whateweris the output kex specified in the transformation configuration intransformations.jsonin your project repository.
Union
To perform union operation, insert the configuration into "union": {} in step.json. Specify the tables to be unioned in the sources list. Note that once a table is included in sources, all the subsequent operation are ignored, i.e. in the following example, "bizzflow-install-gco.raw_ex_mysql_test.table2" would not be copied into "bizzflow-install-gco.in_ex_mysql_test.table2".
Union configuration example:
{
"union": {
"bizzflow-install-gco.raw_ex_mysql_test.table": {
"sources": [
{
"kex": "raw_ex_mysql_test",
"table": "table2",
"project": "bizzflow-install-gco"
}
],
"distinct": false
}
},
"whitelist": {},
"filter": {},
"copy": {
"bizzflow-install-gco.raw_ex_mysql_test.table": {
"incremental": false,
"primary_key": [],
"mark_deletes": false,
"destination": {
"kex": "in_something",
"table": "some_table",
"project": "bizzflow-install-gco"
}
}
}
}
Whitelist
Instead copying whole table, whitelisting enables to select infdividual columns to be copied.
Whitelisting is performed between raw and input stages. To perform whitelisting, insert the table configuration with selected columns into the "whitelist": {} in the step.json in your project repository. Always include the column __timestamp in the list of columns. Separate each table configuration by ,. Additonal info as well as sample configs can be found in README.md in your project repository.
Whitelist configuration example:
{
"union": {},
"whitelist": {
"bizzflow-install-gco.raw_ex_mysql_test.table": {
"columns": ["colunm1", "column6", "column7", "__timestamp"]
}
},
"filter": {},
"copy": {
"bizzflow-install-gco.raw_ex_mysql_test.table": {
"incremental": false,
"primary_key": [],
"mark_deletes": false,
"destination": {
"kex": "in_something",
"table": "some_table",
"project": "bizzflow-install-gco"
}
}
}
}
Filter
Filtering a table means configuring which rows should be included in a table. It is equivalent to applying a ‘WHERE’ condition on a table. There are two ways of configuring the filter: by specifying the columns and the filtering criteria in the list of columns or by specifying custom_query:
- Specifying filtering conditions in
columns: if multiple columns are specified, all the conditions must hold (equivalent to ‘AND’ operator)column: name of the column to be filteredcondition: filtering condition, e.g.>,<,=,!=,LIKE,NOT LIKEvalue: value to be compared with the column value, it is compared as a string (so consider casting column to the desired type)type: type of the column, you want to cast as i.e.int,float,date,string,bool(if not specified or empty, the type is inferred from the column type in the table)
- Specifying
custom_query: if you need to specify more complex filtering condition, you may use custom query in the same way as in SQL ‘WHERE’ condition. - If both,
columnsandcustom_queryare specified,custom_queryis used. If you usecolumnsfilter, do not includecustom_queryin the table filter configuration and vice versa.
Filter configuration example:
{
"union": {},
"whitelist": {},
"filter": {
"bizzflow-install-gco.raw_ex_mysql_test.tables": {
"columns": [
{
"column": "some_column",
"condition": ">",
"value": "0",
"type": ""
}
],
"custom_query": "(`some_column` > 0 OR `another_column` = '10') AND `column_xy`!='some_string'"
}
},
"copy": {
"bizzflow-install-gco.raw_ex_mysql_test.table": {
"incremental": false,
"primary_key": [],
"mark_deletes": false,
"destination": {
"kex": "in_something",
"table": "some_table",
"project": "bizzflow-install-gco"
}
}
}
}
Copy
There are several options how individual table is copied:
| Key | Type | Description |
|---|---|---|
| type | string | transformation type (currently only sql type is supported) |
| incremetal | bool | true for incremental copy, false for full |
| primary_key | list of strings | list of column names to create composite primary key from |
| mark_deletes | bool | markes deleted rows as ‘D’ in last_operation column instead of deleteing the row, relevant for incremental copy only |
| destination | dict | destination table |
Copy configuration example:
{
"union": {},
"whitelist": {},
"filter": {},
"copy": {
"bizzflow-install-gco.raw_ex_mysql_test.table": {
"incremental": false,
"primary_key": [],
"mark_deletes": false,
"destination": {
"kex": "in_something",
"table": "some_table",
"project": "bizzflow-install-gco"
}
}
}
}
project attribute’s function in destination object is dependent on the actual analytical warehouse
used for your Bizzflow project. In BigQuery it is the GCP project ID, in most of the other warehouse types
it is the database name. This attribute will likely be renamed and made optional in the future Bizzflow
releases.Example: Incremental processing
Since usually a large portion of what is called a “big data” do not tend to change much, a very common use-case
is processing (or extracting) only a portion of the data in order to save processing time and power. This can
be achieved thanks to Bizzflow’s step.
Imagine a situation where you have lots of data in your data source partitioned by date. Since your data pipeline runs every day, you do not need to extract data that were already extracted in previous runs. Instead, you would like to download a last day’s (or a few days') worth of data and “paste” it on top of the data extracted during previous runs.
Similar situation was described in ETL Process Structure chapter previously. As seen in the picture below, we were describing a process where only last month’s worth of data were added to a snapshot.
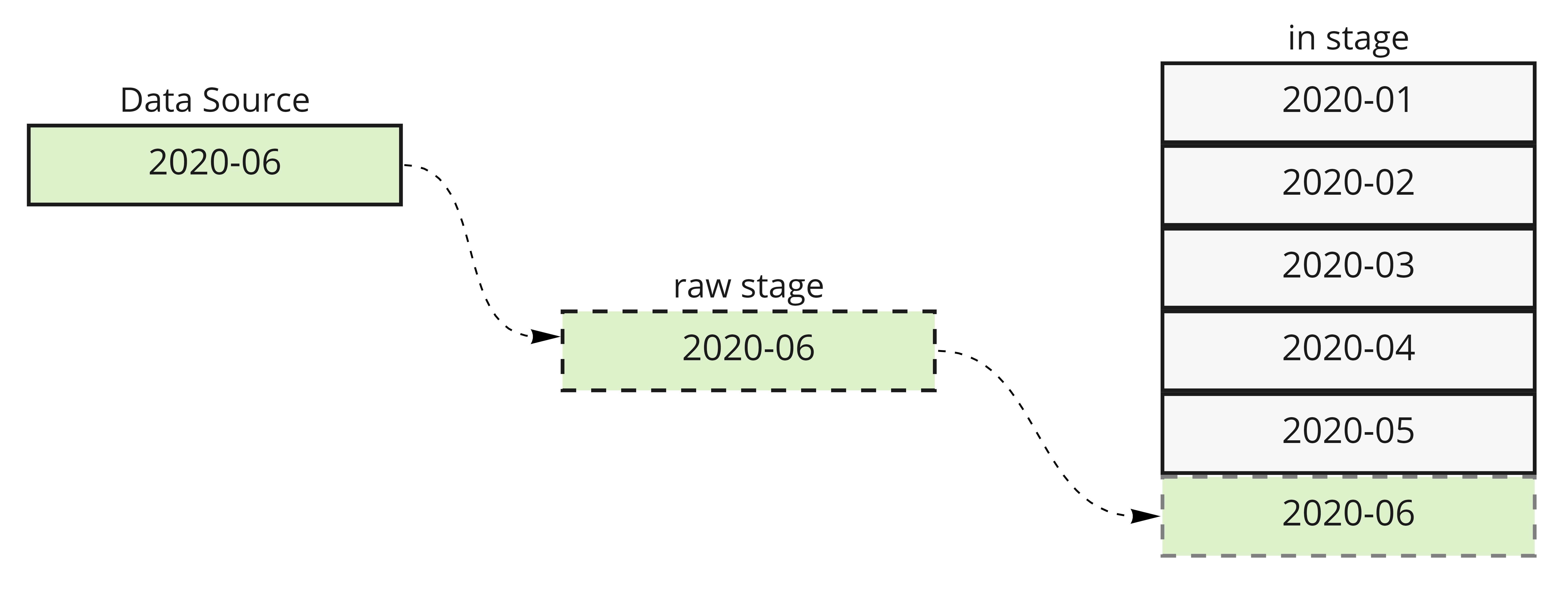
Let’s say we have an extractor set up, downloading last day’s data from MySQL:
/extractors/db.json
{
"type": "ex-mysql",
"config": {
"host": "mydb.com",
"user": "dbuser",
"password": "#!#:mysql-db",
"database": "mydatabase",
"query": {
"invoices": "SELECT * FROM `invoices` WHERE `invoice_date` > CURDATE() - INTERVAL 1 DAY"
}
}
}
In a real-life scenario, you would not use asterisk * in your SELECT statement but a list of columns instead.
Also, we really recommend extracting more than a single day’s worth of data. Errors and mistakes happen, it is a good practice to set your INTERVAL to at least 3 days.
/step.json
{
"union": {},
"whitelist": {},
"filter": {},
"copy": {
"nimble-value-34240.raw_ex_mysql_db.invoices": {
"incremental": true,
"primary_key": ["invoice_id"],
"mark_deletes": false,
"destination": {
"kex": "in_main",
"table": "invoices",
"project": "nibmle-value-34240"
}
}
}
}
After running this on June 2nd, you should have all of June 1sts invoices in in_main.invoices
table. On the next day, there should be invoices for dates June 1st and June 2nd and so long.