Key Concept
Created: May 14, 2021, Updated: March 17, 2022
Bizzflow is a data pipeline tool for every use case.
Get Started with Bizzflow
Before starting with Bizzflow, you should take some time to take a look at the Key Concept figure below in order to understand the basics of what Bizzflow is, what it does and how does it do.
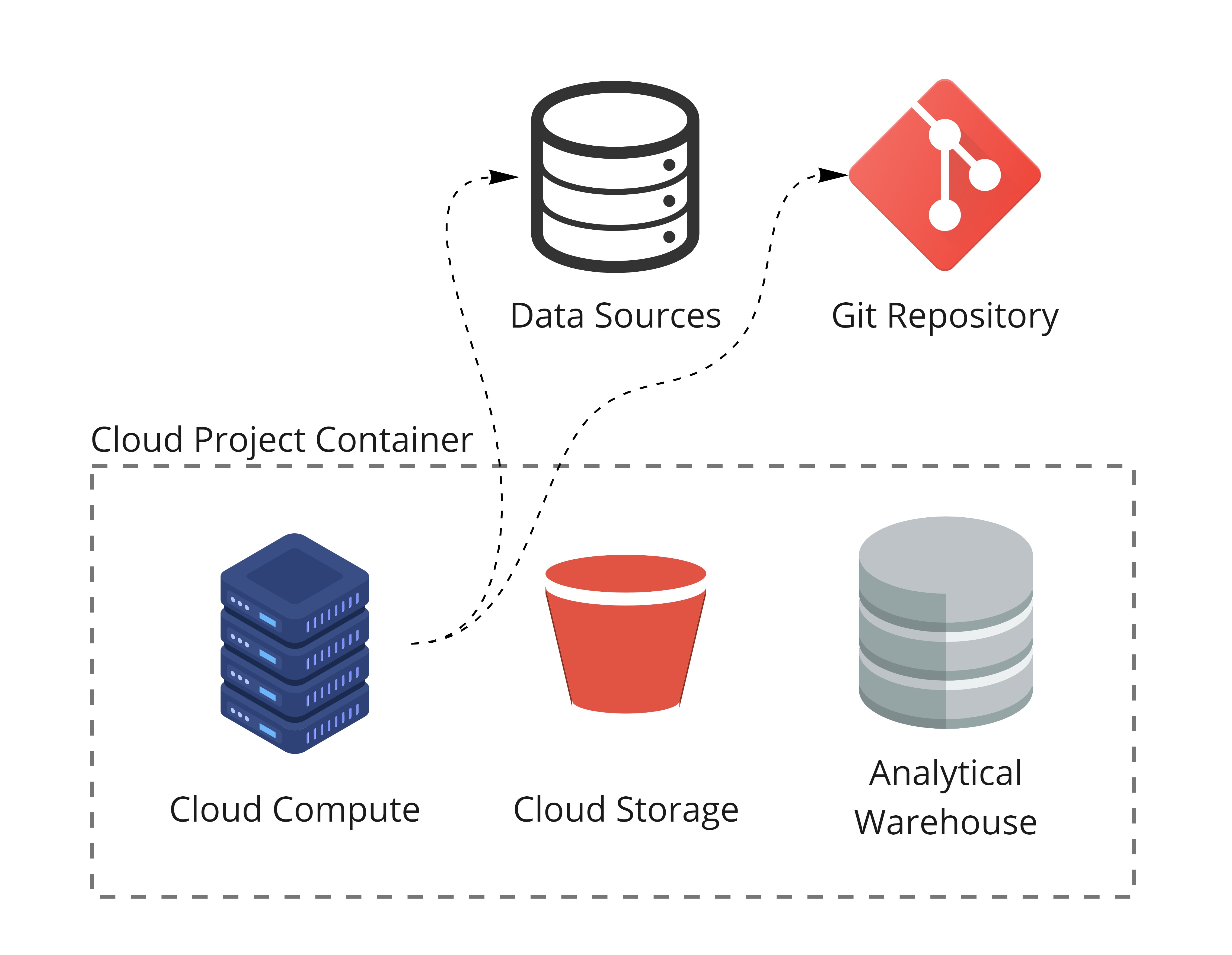
As seen in the simplified picture above, there are few components that come into play when talking about a Bizzflow project.
Components
Data Sources
Data sources represent your primary data in their native location. Be it a Google Spreadsheet,
a table in a database or an endpoint of an API, Bizzflow can extract data from it.
Git Repository
Every Bizzflow project must have a git repository that contains your SQL files,
JSON or YAML configuration and your project documentation.
Cloud Project Container
Bizzflow runs in a cloud environment. It doesn’t matter whether it’s a Google Cloud Platform project,
a Microsoft Azure resource group or Amazon Web Services account. You need an access to your cloud
project container in order to install Bizzflow and set it up.
In the container there will always be at least three main resource types - Cloud Compute, Cloud Storage
and Analytical Warehouse.
Cloud Compute
Cloud Compute is a service providing us with Virtual Machines. We usually use two of those:
airflow- runs a 24/7 Apache Airflow’s scheduler and every few seconds or so tries to figure out whether there are any tasks that are supposed to run
- also provides you with a user interface to monitor your tasks and run them on demand
worker- get started every time there is some heavy lifting to be done
- basically runs whenever an extractor od Docker transformation tasks run
Cloud Storage
Cloud Storage can be understood as a cloud file storage. Bizzflow uses this storage to
store CSV files and logs. You will mostly be able to ignore this resource as our Virtual Machines
deal with without any need of interaction.
Analytical Warehouse
Analytical warehouse is the place where the magic happens. All the data extracted from your data sources will be
available to you in your warehouse. You can write SQL transformations that will run within the warehouse
and finally you can create a datamart, which is a separate space within your warehouse you may use
to make your output data available to 3rd party tools (such as visualization tools).
Operations
Components communicate with each other, while most of the communication is initiated by the scheduler running
within Cloud Compute.
In a nutshell, the data pipeline starts with your Data Source. Bizzflow extracts data from the Data Source
in an operation called extraction and places it as CSV files in the Cloud Storage. Then the CSV files
get loaded into the Data Warehouse in the form of tables.
If you opt to go with the ETL approach, you can write SQL transformations that will run within the
Data Warehouse, creating output tables you can use in 3rd party tools (such as visualisation tools).
Alternatively, if you prefer the ELT approach, you may use Bizzflow to orchestrate
dbt and create views and dbt models instead.