ETL Process Structure
Created: May 15, 2021, Updated: March 17, 2022
Bizzflow comes with the best practices of Data Quality Assurance built in its core. In this chapter, we will cover the basics of the warehouse's structure.
Warehouse Structure
It doesn’t matter which of the supported warehouses you use, Bizzflow always comes with the same structure. Because the terminology differs amongst various warehouses, we came up with few terms of our own in order to unambiguously label the parts of the structure.
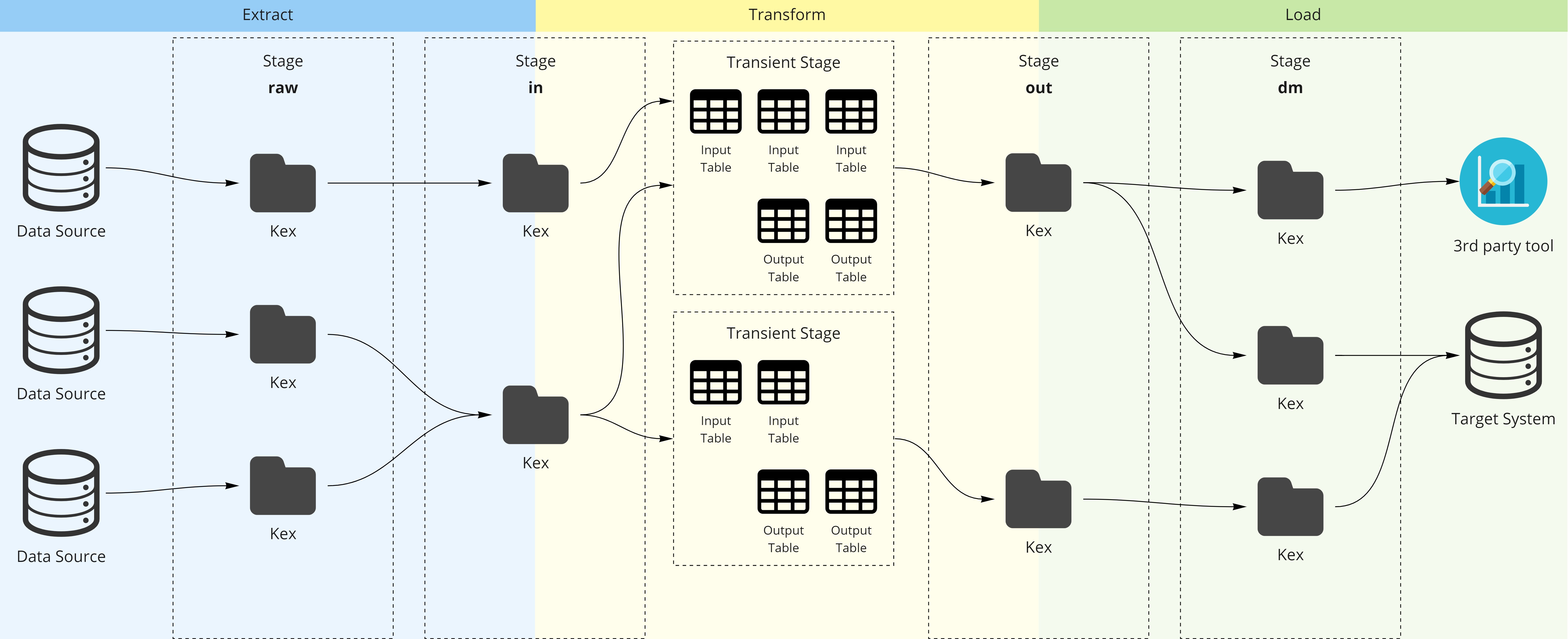
What you see in the picture right above is what a small-scale Bizzflow project may look like from the perspective of the warehouse.
You cat see we’ve got multiple data sources, then some magic happens and then we have a 3rd party visualisation tool and a target system using our data. But what does happen in between?
Stages
When you decide to consolidate data from different data sources, they will always come
in different shape and data quality. Well, let’s face it, they will be mostly dirty.
There will be values missing from your spreadsheet’s cells, null datetimes in your
database’s tables and your proprietary system’s API only returns last month’s data.
raw
All this mess ends up being tables in the raw stage. raw stage always contains
the data in the exact state and for as they came from the primary data source. This way
you can always take a look at what the data looked like before all processing within
Bizzflow project. This is crucial when investigating errors in your data pipeline.
in
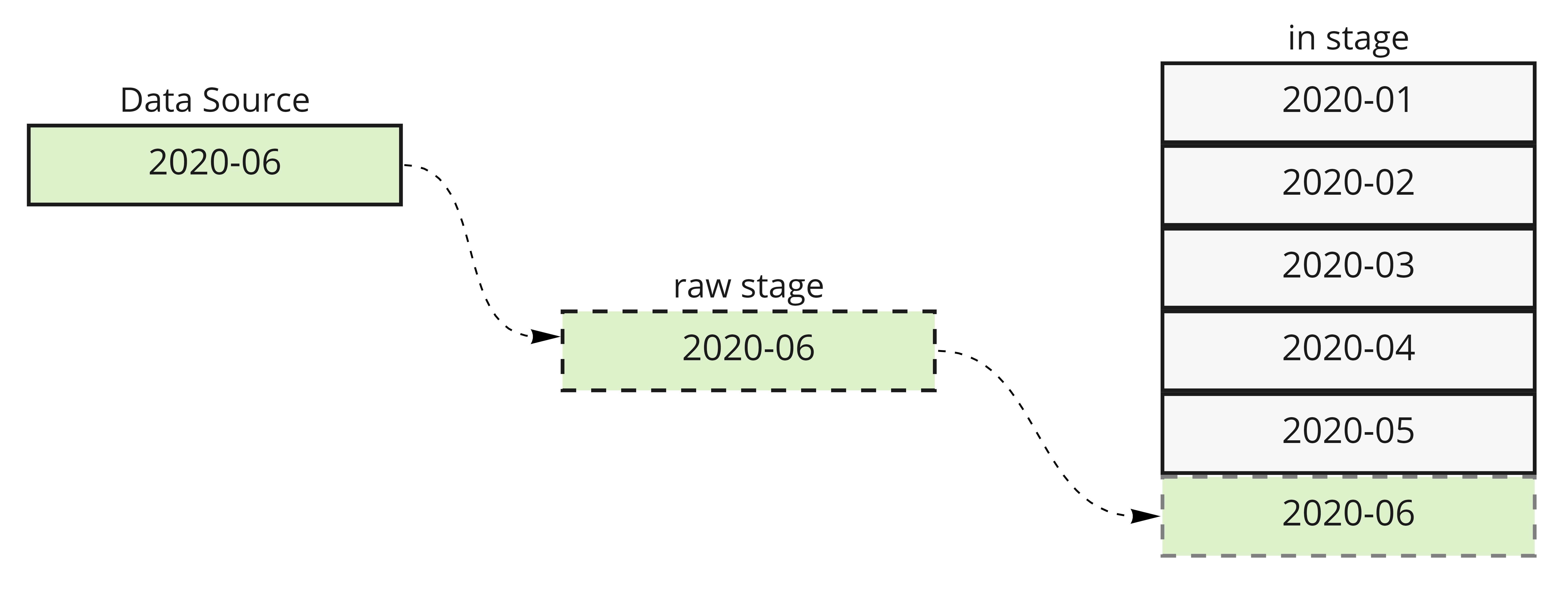
You can deal with your API’s behaviour using Bizzflow’s Step.
Thanks to Step’s increment configuration you may download last month’s data and every
single increment of this data will be present in the raw stage, while the in stage
will contain the complete data for all of the history. in stage always contains
the data that are ready to be used in transformations.
tr
Not exactly a stage, because transformation or tr stage is transient, meaning it only
exists temporarily. When you want to transform data from the in stage, Bizzflow
creates a copy of them in a temporary stage, executes all SQL scripts of your
transformation and outputs any table, that has out_ prefix to out stage.
out
Output stage labels the data in it as processed data, meaning they are to be further used in production.
dm
Datamart stage provides an additional way to distinguish between different kinds of output data.
Imagine you are processing all your company’s data from all data sources. You run them
through various transformations using multiple SQL scripts and you create outputs based
on your company’s departments. Everything works well when separated like this for the purpose
of your Tableau repoting. But for the sake of your sales' internal CRM system, you need some
of your marketing’s data. Mixing all of your sales' and all of your marketing’s data is insecure.
You can create separate datamart for this specific use case and make
sure you don’t leak all of your marketing’s data and provide them to the sales.