Transformation
Created: May 14, 2021, Updated: March 28, 2023
We already have our data in the storage, now it’s time to transform it.
As stated in the Project design chapter, transformations are configured
in the file transformations.json, while the SQL queries live under transformations/{some-folder}/*.sql. Let’s
take a look at transformations.json first.
Transformation configuration
This is what a basic settings of transformations.json looks like:
transformations.json
[
{
"type": "sql",
"source": "{some_folder}",
"id": "{transformation_name}",
"in_kex": [
/* List of input kexes*/
],
"out_kex": "{output_kex_name}",
"in_tables": [
/* List of input tables */
],
"query_timeout": 600
}
]
As you should now, [] brackets in JSON mean array and that means this is a thing, that there can be more of.
If you would like to specify more transformations, you simply add one after the first one:
transformations.json
[
{
"type": "sql",
"source": "{some_folder}",
"id": "{transformation_name}",
"in_kex": [
/* List of input kexes*/
],
"out_kex": "{output_kex_name}",
"in_tables": [
/* List of input tables */
],
"query_timeout": 600
},
{
"type": "sql",
"source": "{another_folder}",
"id": "{another_transformation_name}",
"in_kex": [
/* List of input kexes*/
],
"out_kex": "{output_kex_name}",
"in_tables": [
/* List of input tables */
],
"query_timeout": 600
}
]
However, for the sake of this guide, let’s stick with just one transformation.
Parameters' explanation
type
For the sake of this guide, transformation type will always be sql. Other possibility is docker, but Docker
transformations will not be covered by this guide.
source
Transformation source is the name of the sub-directory within directory transformations/ where SQL files will
be found.
├── transformations
│ └── main
│ ├── 01_orders.sql
│ └── 02_account.sql
└── transformations.json
In case of the file structure above, the name of source would be main.
id
This is the name of the transformation. Please, stick with numbers, English alphabet letters and underscores.
As stated above, it is a good practice to keep the name related to the source and otherwise.
Also, id is limited by
naming
rules.
Input
Keys in_kex and in_tables are both arrays that accept an arbitrary list of kexes and tables respectively.
You can specify kexes by their names and tables in the form of kex_name.table_name. If you specify a kex, all
tables from the kex will be available to the transformation.
Output
Parameter out_kex specifies the name of the output kex. All tables prefixed out_ will be copied to this kex
after the transformation end.
Query timeout
So far, this is only a BigQuery-specific setting that specifies how many seconds to wait for the query result at most. You can ignore this for now, default 600 means maximal duration of a query will be 10 minutes.
Putting it together
Let’s call our transformation main, since there will only be one and name our source main as well to keep
things clean. Let’s input only tables orders and orderdetails from our classicmodels extractor. Third time
is the charm, so let’s our output kex call main as well.
transformations.json
[
{
"type": "sql",
"source": "main",
"id": "main",
"in_kex": [],
"in_tables": [
"in_ex_mysql_classicmodels.orders",
"in_ex_mysql_classicmodels.orderdetails"
],
"out_kex": "out_main",
"query_timeout": 600
}
]
To actually see the transformation, do not forget to run 90_update_project DAG again.

Writing the SQLs
We cannot run the transformation yet, because we havent’s actually written any SQL files yet (the
transformations/main/ directory is still empty).
Setting the sandbox up
The best way to develop SQLs on your data is loading the transformation into sandbox. Sandbox is an exact
replica of the input data for the transformation with accessible credentials, so that you can connect to the sandbox
and run queries before commiting them to the repository. Let’s open up Sandbox Flow UI page
(Flow UI -> Sandbox).
Select main from the transformations list and run sandbox by pushing Load sandbox button.
By default, sandbox names are created with dev_ prefix, then first three letters from your first name and three
letters from your last name (dev_tomvot for me).
Sandbox credentials
You can access you sandbox credentials using
Vault page in Flow UI. Find your sandbox
name in Sandbox & Datamarts section of the Vault. It should look like this:
{
"type": "service_account",
"project_id": "bizzflow-r2-training",
"private_key_id": "private_key_id",
"private_key": "private_key",
"client_email": "dev-tomvot@bizzflow-r2-training.iam.gserviceaccount.com",
"client_id": "client_id",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://oauth2.googleapis.com/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/dev-tomvot%40bizzflow-r2-training.iam.gserviceaccount.com"
}
Never share your sandbox credentials with anyone. They can be used to access project data.
Let’s connect to the sandbox.
Connecting to sandbox
In the DBeaver, select Create connection and pick Google BigQuery from the list of databases.
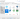
As the Project specify the project_id from your credentials file downloaded above, in Service account specify
client_email and lastly browse for the key path and select the file downloaded above.
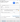
Confirm everything using Finish button.
Looking around
You should now be able to display tables you have in your sandbox.

Just like we specified in in_tables in the transformations.json file, there are only two tables in our
transformation sandbox. Both tables have in_ prefix so that it is super easy for us to differentiate
between tables that came as the input for out transformation and ones that were created within the transformation
itself. Press F3 to open a new SQL file and type this:
SELECT * FROM `dev_tomvot`.`in_orders`;
Replace
dev_tomvotwith the name of your sandbox.
Now press Alt + X and you should see the content of the in_orders table.

The queries
We could spend days cleaning the data and getting them ready for processing, but this is not the goal of this guide.
Let’s just say we do not like the null on the tenth line in shippeddate column, so let’s correct it:
SELECT
`ordernumber`,
`orderdate`,
`requireddate`,
CASE
WHEN `shippeddate` = '' THEN '1970-01-01'
ELSE `shippeddate`
END as `shippeddate`,
`status`
FROM
`dev_tomvot`.`in_orders`;
In order to actually have the result of the query in our transformation, let’s persist the SELECT as a table:
CREATE OR REPLACE TABLE `dev_tomvot`.`cln_orders` AS
SELECT
`ordernumber`,
`orderdate`,
`requireddate`,
CASE
WHEN `shippeddate` = '' THEN '1970-01-01'
ELSE `shippeddate`
END as `shippeddate`,
`status`
FROM
`dev_tomvot`.`in_orders`;
From now on, we should have cln_orders table containing our cleaned input data. Let’s do the same with
orderdetails:
CREATE OR REPLACE TABLE `dev_tomvot`.`cln_orderdetails` AS
SELECT
`ordernumber`,
`productcode`,
`quantityordered`,
`priceeach`,
`orderlinenumber`,
CAST(`quantityordered` as INT64) * CAST(`priceeach` AS FLOAT64) as `total_price`
FROM
`dev_tomvot`.`in_orderdetails`
;
Now let’s produce a single table containing all of our desired data:
CREATE OR REPLACE TABLE `dev_tomvot`.`out_order_lines` AS
SELECT
d.`orderlinenumber`,
o.`ordernumber`,
o.`orderdate`,
o.`shippeddate`,
d.`productcode`,
d.`quantityordered`,
d.`total_price`,
d.`priceeach`
FROM `dev_tomvot`.`cln_orders` o
LEFT JOIN `dev_tomvot`.`cln_orderdetails` d ON o.`ordernumber` = d.`ordernumber`
;
After running all the queries and testing the output, do not forget to change the dataset name from dev_tomvot to tr. This is a substitute name meaning “whatever the transformation dataset will be named”. This is inconvenient, but needed due to BigQuery not being able to set default dataset (every table has to have one explicitly specified).
You can do this easily by pressing CTRL + H, filling `dev_tomvot` in the Containing text field and hitting Replace… button. In the next screen fill `tr` in the With: field as shown in the pictures below.
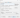

Saving the queries
Let’s put our resulting queries into our Bizzflow project repository in two files:
transformations/main/01_clean.sql
CREATE OR REPLACE TABLE `tr`.`cln_orders` AS
SELECT
`ordernumber`,
`orderdate`,
`requireddate`,
CASE
WHEN `shippeddate` = '' THEN '1970-01-01'
ELSE `shippeddate`
END as `shippeddate`,
`status`
FROM
`tr`.`in_orders`;
CREATE OR REPLACE TABLE `tr`.`cln_orderdetails` AS
SELECT
`ordernumber`,
`productcode`,
`quantityordered`,
`priceeach`,
`orderlinenumber`,
CAST(`quantityordered` as INT64) * CAST(`priceeach` AS FLOAT64) as `total_price`
FROM
`tr`.`in_orderdetails`
;
transformations/main/02_process.sql
CREATE OR REPLACE TABLE `tr`.`out_order_lines` AS
SELECT
d.`orderlinenumber`,
o.`ordernumber`,
o.`orderdate`,
o.`shippeddate`,
d.`productcode`,
d.`quantityordered`,
d.`total_price`,
d.`priceeach`
FROM `tr`.`cln_orders` o
LEFT JOIN `tr`.`cln_orderdetails` d ON o.`ordernumber` = d.`ordernumber`
;
Now you can commit all changes and run 90_update_project DAG to refresh our queries. It’s time to run
the transformation.
Running the transformation
Our queries are ready, project was updated, let’s run the transformation.

Run 40_Transformation_main DAG. After it has ended, look into Storage page of Flow UI. After clicking Refresh kexes
button, you should see a new kex appear, named out_main, containing only single table order_lines.

Easy-peasy, am I right?
So that was our first transformation. Go get yourself a steaming hot chocolate ☕ and then continue to the next chapter.