Project Design
Created: May 14, 2021, Updated: November 28, 2022
This chapter will hopefully help you understand, what makes your data appear in the storage, how you make Airflow UI display more DAGs and uncover the remaining mysteries of Bizzflow.
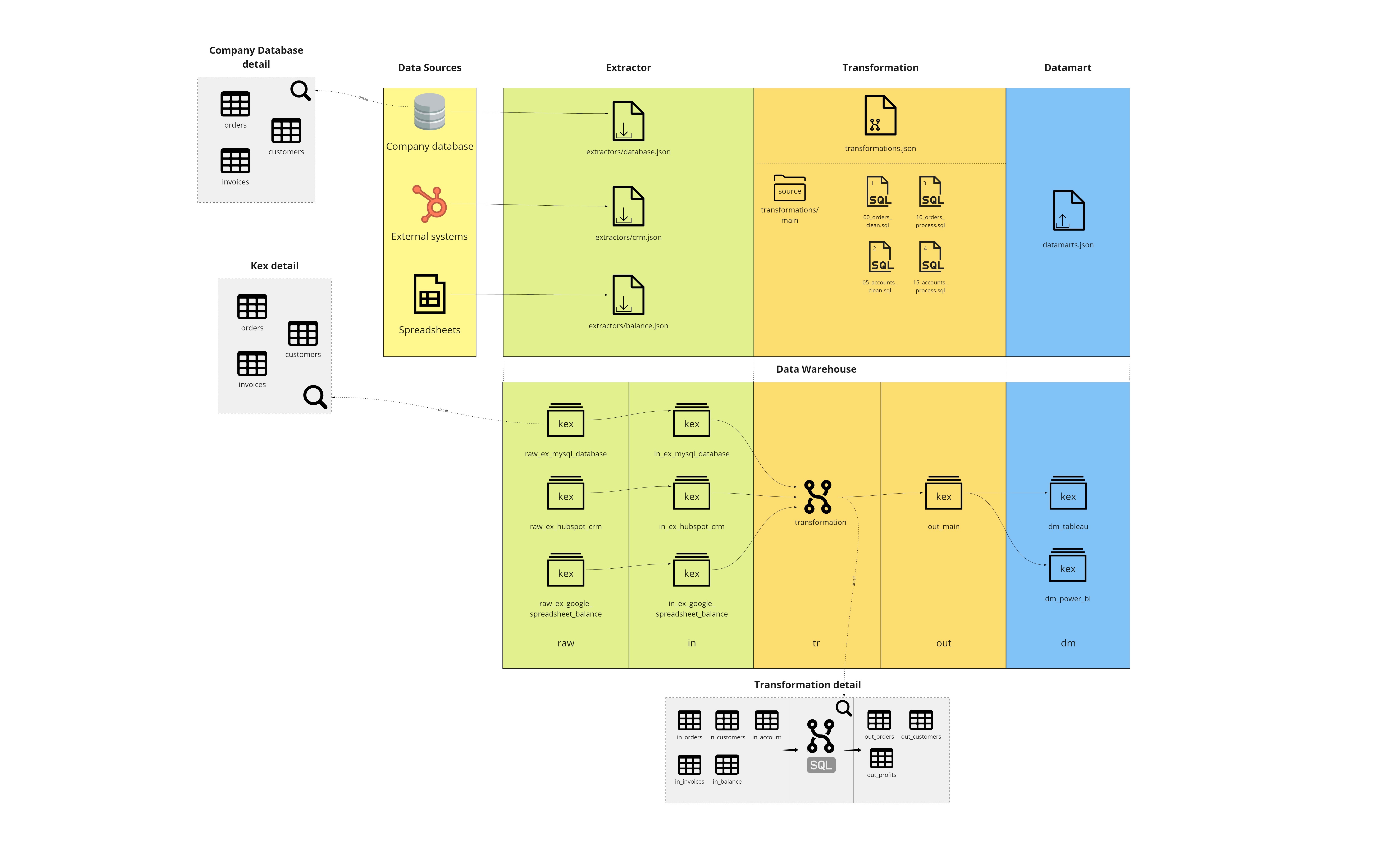
If you feel dizzy after looking at the picture above, feel free to chill out. Although it may look difficult when drawn in a diagram, the design is made to be as easy for the user as possible. We will use this chapter to gradually walk through parts of the picture in order to make you understand every part just enough to be able to know where to look to achieve anything you would like to.
Data Sources

Let’s look closely at the topleft part of the image with three data sources. These repressent any data source, you may possibly need to process using Bizzflow. Bizzflow does not care how many of them you have, you may only need one, for some use-cases there may be tens, for edge-cases there may even be none.
Databases
Lots of companies keep their data in some kind of database. As of now, Bizzflow supports a variety of SQL and NoSQL databases (such as PostgreSQL, MySQL, MariaDB, Microsoft SQL Server, CosmosDB, Firebird, etc.).
Please keep in mind, that if you want to connect to any of those databases, there needs
to be a network access to them from your Bizzflow project. Take a look
at Key Concept chapter of
Bizzflow wiki, you’ll see that the connection to your data source is performed by
a Docker Worker. This worker always runs on static IPv4 address, that must be
whitelisted on your database’s firewall.
If you do not know how to do that, refer to the person that managages your company’s database.
If you are just trying to do this on your own, try searching Google
for managing access to <your database type>.
External systems
From CRMs through ERPs and CMSs to any other possible scary abbreviation you may be using, this kind of data source is also well supported by Bizzflow.
If you need to get your data from Hubspot, Salesforce, Facebook, Sklik and many more, know, that Bizzflow is there for you.
Spreadsheets
Let’s face it, you have data in a spreadsheet. Sometimes you just need to quickly put up a table to take
a look at your ad-hoc data. Sometimes companies run their analytics on spreadsheets. We do not like it, we do not
encourage it, but we understand that it happens. If you have your data stored on Google Drive or OneDrive,
Bizzflow’s got you covered.
Others
Didn’t we mention something you need? Take a look at the list of officially supported data sources and know that we keep on adding regurarly. If you still do not see what you like, let us know at community@bizzflow.net.
Extractor

Extractor in Bizzflow is a component that will connect to your data source and download data to your storage. There are things that are common for every data source you may need to connect, please make sure you know these things before trying to connect to a data source:
- data source type
- e.g.
MySQL Database MS SQL Server DatabaseGoogle SheetHubspotetc.
- e.g.
- data source credentials
hostorserver,userandpasswordfor databases- various services enable access using
API keysortokens - some services allow connecting using
usernameandpassword - services using OAuth credentials may require
service account key - you will find out which kind of credentials you need from the extractor component’s documentation
- the source
- list of actual
tablesyou wisth to download fromdatabase endpointsyou wish to download from specific API (e.g.contactsfromHubspot)linkto a sheet within Google Drive or OneDrive
- list of actual
As you may have noticed in the previous chapter, your Bizzflow project’s
repository contains a directory named extractors. This is a folder that will contain all the information Bizzflow
needs to connect to the datasource. Following file structure corresponds with the
Extractor image above:
extractors/
├── balance.json
├── crm.json
└── database.json
Each of the files contains information on what kind of data source to connect to, how to connect to it and what
data to download from it. So, for instance, crm.json would contain informations such as:
connect to Hubspot using this API key and download list of contacts and pipelines
Of course, Bizzflow does not understand such high level of English. That is why all the configurationn files are
written using JavaScript Object Notation, known by its abbreviation JSON.
This guide presumes that you already know how to write JSON with your bare hands and that you understand written
JSON without problems. If you do not, please take your time to walk through
this tutorial.
Extractors' storage implications
If you were to run three preceding extractor configurations, it would manifest in the Bizzflow storage like this:

raw
As you can see, there are three kexes in the raw stage. Each of the kex represents a single extractor component
configuration and contains all tables that the component extracted from the data source.
E.g. if you had three tables in your MySQL database configuration, these three tables would now be present in the
raw_ex_mysql_database kex.

in
By default, any table that gets created in any raw kex will be copied to the in stage as well. That way
once your data is downloaded and staged in the raw stage, you can be sure they exist in the in stage and can be used in your transformations, as this guide will show you in a moment.
There are multiple ways you can customize the way the data gets copied to the in stage, but we will not tackle
them in this guide yet. The default behaviour should suffice for most basic cases.
Naming conventions
You may have already noticed the names of the default kexes. Let’s take a look at these names: raw_ex_mysql_database and in_ex_mysql_database.
You probably see that the kex name begins with the stage name. This is actually not only a default but also a great practice that Bizzflow enforces. That way you always know what data quality your tables actually are by the name of the kex.
After the first underscore, there is a word ex which is actually an abbreviation of extractor and specifies that
the data that the kex contains came from an extractor component.
The third part of the kex name is the type of the component. This is inferred from the component configuration itself. We will see how to write extractor configurations in the next chapters.
Last part of the kex name is an id of the extractor component. The id is inferred from the file name that the
extractor configuration lives in. For our database.json, crm.json and balance.json files, three kexes ending
with each of the files’s name respectively.
The naming convention as we described it above is:

{stage}_{origin}_{component_type}_{configuration_id}
You are not obliged to follow this naming convention, although you are encouraged to do so. From our long-term practice it is our experience that keeping the kexes’s names clean is essential in order to maintain larger projects.
Transformation

Transformation defines a process during which data is being cleaned, enriched, prepared for visualisation; in one word: transformed. Bizzflow allows you to have any number of transformations on any data you wish to transform, although this guide will focus on creating one.
In your Bizzflow project repository, there is a file called transformations.json and a directory named
transformations as well.
In transformations.json you define transformations' metadata; which tables from your in stage should Bizzflow
prepare for your transformation, what kex the resulting tables should end up being created in and where do you keep
SQL files.
In transformations directory, you create a directory for every one of your transformations and put your SQL files
there. The structure of your future project may look like so:
├── transformations
│ └── main
│ ├── 00_orders_clean.sql
│ ├── 05_accounts_clean.sql
│ ├── 10_orders_process.sql
│ └── 15_accounts_process.sql
└── transformations.json
Imagine you have a transformation called main, Bizzflow will know to look for SQL files in the main sub-directory
of the transformations directory.
We will tackle this more thoroughly in one of the next chapters.
Transformation in details

In theory, when you run a transformation in Bizzflow, what happens is that tables that you defined in the
transformation’s configuration are copied to a temporary schema in which the tables are transformed based on SQL
files you specify. After the transformation run, every table with out_ prefix that may have been created during the
transformation will be copied to specified out kex.
Datamart
The only way to access data in Bizzflow Storage is through the
Flow UI’s Storage page. You may look at the tables,
display their preview and columns' definition, but there is no way to actually access the data
from a 3rd party tool. At least when talking about raw, in and out stages.
If you need to access the processed data using, let’s say, a visualisation tool (like Tableau, GoodData or Power BI), you will need a datamart.
Imagine a scenario in which you process your company’s data in a single or more transformations and end up having
multiple out kexes for each of your company’s office. There is a kex out_finance that contains the data your
CFO needs for planning and balance sheet review. Then there is a kex out_sales containing performance data
about salespeople in your company. And, finally, tere is a kex out_general with plans vs. actuals, KPIs and so long.
You wish to give access to every single one in your company to the data in out_general but would like to keep
sales and financial data confidential.
In a similar scenario, you have exactly that but in a single out kex named out_main that contains all the output
tables from your transformation.
What datamarts do is that they keep a copy of the specified data completely isolated from the rest of your Bizzflow project, so that you do not have to be afraid to share credentials or put them in your visualisation tool.
Ready to move on
And that’s it! Right now you should be able to look at the picture above and understand what is what. You are now ready to move to the next chapter.