Extractors
Created: May 14, 2021, Updated: November 28, 2022
As stated in the chapter Project Design, extractors are components, that download data from your data source. In this chapter, we will update our Bizzflow project so that it know how to extract data from Relational Dataset Repository maintained by Faculty of Information Technology at Czech Technical University in Prague. The dataset we are going to use is ClassicModels.
Right now, this is what our Airflow UI looks like:

Our goal in this chapter is to add an extractor configuration, so that our Airflow UI looks like this:

Putting the information together
In the previous chapter Project Design, we said that we need at least three pieces of information about our data source in order to make Bizzflow extract data from it - data source type credentials and the source (source tables). Let’s take a look at the way we can find this out.
Data source type
First, we need to know, what is the database backend. From the description of the data source, we see that the
database lives within MySQL (MariaDB) server. Let’s look up MySQL within
Bizzflow extractors repository.

There is only a single result - MySQL extractor.

Open the repository and take note of the repository name. You can find it at either at the end of the URL or next to the branch name (as seen in the picture below).
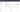
For the MySQL extractor it is ex-mysql. We will need it to tell Bizzflow which component to use when connecting
to our data source.
Credentials
Luckily, we do not have to go to Hell and back for this as the maintainers of the Relational Dataset Repository put the credentials in the bottom of the dataset page.

Source tables
For the purpose of this demo, let’s download every single table, these are namely orderdetails, orders,
payments, products, customers, productlines, employees and offices.
Creating the configuration
We have all the information we need, so let’s put it all together.
Create a new empty file within extractors/ directory in the Bizzflow project repository and name it
classicmodels.json. The structure of extractor configurations JSON files is fairly easy:
extractors/classicmodels.json
{
"type": "{component id}",
"config": {
/* Component-specific extractor configuration */
}
}
We already know component id from
MySQL Extractor component repository - ex-mysql, so we may as
well fill it in:
extractors/classicmodels.json
{
"type": "ex-mysql",
"config": {}
}
This way, Bizzflow will know to use MySQL Extractor when processing this data source.
For the component-specific config we need to take a look at the component repository again and scroll down to the example configuration:

This is the object we will need to “nest” underneath the config key in our extractor configuration:
{
"$schema": "https://gitlab.com/bizzflow-extractors/ex-mysql/-/raw/master/config.schema.json",
"user": "patrik",
"password": "12345",
"host": "mysql-db.cz",
"database": "customers",
"query": {
"table_name": "SELECT * FROM table_name"
}
}
$schema key can be omitted in the configuration but it helps you,
because some IDEs use it to autocomplete JSON keys for you.All we need to do is fill in our real credentials we got in one of the previous steps, the configuration will look like this:
{
"$schema": "https://gitlab.com/bizzflow-extractors/ex-mysql/-/raw/master/config.schema.json",
"user": "guest",
"password": "relational",
"host": "relational.fit.cvut.cz",
"database": "classicmodels",
"query": {
"orderdetails": "SELECT * FROM `orderdetails`",
"orders": "SELECT * FROM `orders`",
"payments": "SELECT * FROM `payments`",
"products": "SELECT * FROM `products`",
"customers": "SELECT * FROM `customers`",
"productlines": "SELECT * FROM `productlines`",
"employees": "SELECT * FROM `employees`",
"offices": "SELECT * FROM `offices`"
}
}
*) in SELECT statements.
This way, if any of the database’s columns change, you will
know it before the component actually tries to download
the data. Changes in the sources are best to be known as soon
as possible. For the sake of simplicity, we will use the * here.
In this case, do as we say, not as we do.But wait. I don’t think it is a good idea to store password (even though a public one) in the file I am about to commit to a repository (even though it may not be public). The thing is:
You should never commit sensitive information like passwords to any repository. This is a silly thing to do that may lead to leaking sensitive information. Even deleting the password afterwards has no effect because
a) the password may have already been copied b) the password can still be accessed via git history
See this article for more information on this.
The question remains: how do we tell Bizzflow how to connect to the data source if we may not tell it the password?
Luckily, Bizzflow comes armed with a security measure just for this use-case. Open your Flow UI and select Vault.
Click ➕ Create new..., fill in ID and Value so that the id is something easily distinctible and relatable
to extractor configuration and value is our password "relational" and save it.

The way we tell Bizzflow to look into the connection instead of just plainly using the password is by using a special
hash string #!#:{connection id}, in our case this will be #!#:classicmodels.
If you now paste your configuration into our config key within the JSON file, it should look like this:
extractors/classicmodels.json
{
"type": "ex-mysql",
"config": {
"$schema": "https://gitlab.com/bizzflow-extractors/ex-mysql/-/raw/master/config.schema.json",
"user": "guest",
"password": "#!#:classicmodels",
"host": "relational.fit.cvut.cz",
"database": "classicmodels",
"query": {
"orderdetails": "SELECT * FROM `orderdetails`",
"orders": "SELECT * FROM `orders`",
"payments": "SELECT * FROM `payments`",
"products": "SELECT * FROM `products`",
"customers": "SELECT * FROM `customers`",
"productlines": "SELECT * FROM `productlines`",
"employees": "SELECT * FROM `employees`",
"offices": "SELECT * FROM `offices`"
}
}
}
If you commit the changes and merge them to master branch of your Bizzflow project repository, you should be ready
to go along to your Airflow UI.
Running the task
Wait. It still looks like this, doesn’t it?
We wanted to add the extractor configuration, how is it possible, that the DAG is not there yet?
That’s right, we need to run 90_update_project DAG first.
Click on the play button ▶ (Trigger DAG) on the line of the 90_update_project DAG and confirm running it with
Trigger button.
You should see a bright green circle on the 90_update_project line:

90_update_project is enabled - On should be at the begining of the DAG’s line.Try refreshing the page after a while and you should now see the extractor DAG like this:
Again, the DAG will probably appear being
Off, switch it toOnright now.
Nothing should prevent us from running the component now. Click the play button ▶ (Trigger DAG) for our new
20_Extractor_ex-mysql_classicmodels DAG and confirm again by clicking Trigger. The extractor should now be
running. You can either check it via Consoles -> Latest tasks or on the main Airflow UI screen by the light green
circle. Once the circle disappears (or the task status in Latest tasks turns to success), everything
should be done.


See the results
Go to Flow UI’s Storage page and click
Refresh Kexes. Kex in_ex_mysql_classicmodels should appear. When you click the kex name,
you should see the tables that the kex contains.

Well done
We have our extractor configuration, let’s take a deep breath and transform the 💩 out of our data!